|
|
Available as an Add-on for LEADTOOLS Document and Medical Imaging toolkits. |
An Overview of Recognition Modules
OCR Plus
If the automatic recognition module is used, the Engine will try to automatically select the most suitable recognition module for the zone. This is determined just before recognition, according to the zone's filling method and, if necessary, other settings, most typically the Character Set.
The MTX module recognizes machine printed text from printed publications, laser or ink-jet printers, and electric typewriters. Output from mechanical typewriters in good condition, and from draft-quality, letter-quality, or near-letter quality dot-matrix printers is also acceptable.
The fastest of the selectable OCR engines
Supports up to 64 zones on one image
Supports Omnifont, Draftdot9 and Draftdot24 filling methods.
The OmniFont recognition module
detects and transmits bold, italic or underlined text (or any combination)
detects and transmits character size
classifies font types into three broad categories: serif, sans serif and monospaced.
Provides 2 page-level accuracy and speed trade off settings including a combined Accurate & Balanced value and Fast (RECGMD_FAST is respected, while RECGMD_BALANCED and RECGMD_ACCURATE are merged to one value)
Provides Checking Subsystem based correction
Handles A3 size (11.69" x 16.54") portrait and landscape images with 300 dpi resolution. (At larger resolution the supported image size is smaller.)
Supports images with the following resolution ranges: 90-110, 160-240, 280-320, 400, 600. (Does not process images larger than 6600 pixels in width or height.)
Supports character sets for the following languages, singly or in combination: English, Brazilian, Danish, Dutch, Finnish, French, German, Italian, Norwegian, Portuguese, Spanish, Swedish.
The MOR module recognizes machine printed text from printed publications, laser or ink-jet printers, and electric typewriters. Output from mechanical typewriters in good condition, and from letter- or near-letter quality (LQ, NLQ) dot-matrix printers is also acceptable.
Supports up to 500 zones on one image
Supports Omnifont, Draftdot24 and OCR-A filling methods
The OmniFont recognition module
detects and transmits bold, italic or underlined text (or any combination)
detects and transmits character size
classifies font types into three broad categories: serif, sans serif and monospaced
uses contour analysis along with pattern matching to perform recognition
Provides 3 page-level accuracy and speed trade off settings including Accurate, Balanced and Fast (RECGMD_FAST is respected, while RECGMD_BALANCED and RECGMD_ACCURATE are merged to one value)
Provides Checking Subsystem-based correction
Handles A3 paper size (11.69" x 16.54") portrait and landscape images with 300 dpi resolution
Recognizes about 500 characters, including Latin, Greek and Cyrillic alphabets with enough accented letters to recognize the 119 Languages supported by the engine.
There are two ways of modifying incoming images to make them more suitable for this omnifont recognition module:
Standard mode Fax output. (200 x 100 dpi). This switch doubles the pixels in the image’s vertical direction. Faxes sent in Fine Mode (200 x 200 dpi) are preferable. However, if faxes are sent in Fine Mode, then the Standard mode Fax Output should not be used.
Draft 24-pin dot-matrix output. Use the FILL_DRAFTDOT24 filling method to have the character contours smoothed. Again, NLQ or LQ quality output can usually be better recognized without using FILL_DRAFTDOT24.
The Dot Matrix module is designed for ONLY draft-quality 9-pin dot-matrix texts.
For NLQ or LQ texts, the RECOGMODULE_OMNIFONT_PLUS2W, RECOGMODULE_OMNIFONT_PLUS3W, RECOGMODULE_MTEXT_OMNIFONT or RECOGMODULE_MULTI_LINGUAL_OMNIFONT modules are likely to give better results.
If FILL_DRAFTDOT9 filling method is set together with RECOGMODULE_AUTO, RECOGMODULE_MTEXT_OMNIFONT is used, provided that all characters (or languages or filters) validated for the zone are supported by it. If any are not supported, this module is used.
Supports 76 languages, of which 14 have dictionary support: Catalan, Danish, Dutch, English, Finnish, French, German, Greek, Hungarian, Italian, Norwegian, Portuguese, Spanish and Swedish.
Reads multiple languages.
Reads 18 of the 29 punctuation characters. (The Low Double Comma Quotation Mark is missing).
Supports 24 of the 55 miscellaneous characters. (Missing charcters include the Euro Sign, the Small Script F, the Copyright Sign, Registered Trade Mark Sign and the Degree Sign.)
Does not interpret the recognition trade-off setting and cannot be trained.
Used if it is directly specified in a zone structure.
Generates confidence data on recognized characters and can interpret all filter values.
For more information see the LEAD OMR Overview.
The ICR-HNR module can be used for recognition of hand-printed numerals and four additional signs. If further hand-printed characters are to be recognized, the use of the RECOGMODULE_RER_PRINTED recognition module is recommended.
This recognition module can recognize the following hand-printed characters:
Numerical Digits 0–9
Plus Sign (+)
Minus Sign (–)
Period or Full-stop (.)
Comma (,)
The filter ZONE_CHAR_FILTER_DIGIT can be used to exclude the last four characters. The filters ZONE_CHAR_FILTER_PUNCTUATION and ZONE_CHAR_FILTER_MISCELLANEOUS function, other filters have no effect.
The ICR-RER module is a third-party recognition module from reRecognition GmbH, Germany. The Engine contains its recognition engine version 4.2f.
This recognition module can be used for recognition of hand-printed alphanumerical characters, i.e. upper and lower case letters, the digits and some others. Although it can be used to read flowing text, its main application area is in form-like situations, where the form designer has great control over the content and maybe length of hand-printed information given in each zone.
The MAT module is designed to read certain groups of fixed-font characters specially designed for OCR or imaging applications, in which no two characters have similar shapes. Each character group has its own filling method. Application areas are in banking, check or waybill handling, product distribution and document validation, where high accuracy can be vital. It also handles some non-fixed print styles.
FILL_OCRA
OCR-A. Uppercase English letters (26), digits, some punctuation, and 3 special OCR-A symbols:
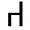 (OCR Chair)
(OCR Chair)
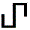 (OCR Hook)
(OCR Hook)
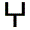 (OCR Fork:)
(OCR Fork:)
FILL_OCRB
OCR-B. Uppercase English letters (26), digits and some punctuation.
FILL_MICR
MICR (E-13B). Digits plus some punctuation and 4 special MICR symbols:
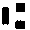 (OCR Branch
Bank)
(OCR Branch
Bank)
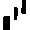 (OCR Amount
of Check)
(OCR Amount
of Check)
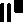 (OCR Dash)
(OCR Dash)
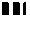 (OCR Customer
Account Number)
(OCR Customer
Account Number)
FILL_DOTDIGIT
Ten digits only and the period. Commas are also read, but converted to periods. Though this is in theory a fixed-font, many variants of it are used.
FILL_DASHDIGIT
Ten digits only and the period. Commas are also read, but converted to periods. Though this is in theory a fixed-font, many variants of it are used.
The FRX module recognizes machine printed text from printed publications, laser or ink-jet printers, and electric typewriters. Output from mechanical typewriters in good condition, and from letter- or near-letter quality (LQ, NLQ) dot-matrix printers is also acceptable.
Optimized for speed
Supports up to 2,500 zones on one image
Supports Omnifont filling methods
Supports Latin, Greek and Cyrillic alphabets with enough accented letters to recognize the 54 languages (Languages and modules)
The PLUS modules recognize machine printed text from printed publications, laser or ink-jet printers and electric typewriters. Output from mechanical typewriters in good condition may also be acceptable.
The PLUS2W and PLUS3W modules use voting technology to provide improved recognition results.
The PLUS2W module combines the results from the MOR and MTX modules.
The PLUS3W module combines the results from the MOR, MTX and FRX modules.
With either of these two voting modules, the accuracy is considerably better, but the recognition may need significantly more time than any single module.
Note: The Plus engine has global and module specific limits on image size. The global (meaning on loading) limits are 8400 pixels and 22 inches. Some of the OCR modules have even lower limits. The most limiting modules are MOR and MTX. Both have a hard coded upper limit. The limit is 5440 pixels in the case of MOR and 6688 for MTX. MTX has an additional limit based on the image area. It is limited to 20 megapixels (in practice this means something near 4000x5000 pixels).
OCR Professional
If the automatic recognition module is used, the engine will try to automatically select the most suitable recognition module for the zone. This is determined just before recognition, according to the zone's filling method and, if necessary, other settings, most typically the Character Set.
The MTX module recognizes machine printed text from printed publications, laser or ink-jet printers, and electric typewriters. Output from mechanical typewriters in good condition, and from draft-quality, letter-quality, or near-letter quality dot-matrix printers is also acceptable.
Supports Omnifont filling methods.
The OmniFont recognition
module
- Detects and transmits bold, italic
or underlined text (or any combination)
- Detects and transmits character size
- Classifies font types into three broad categories: serif, sans serif
and monospaced.
Provides two page-level accuracy and speed trade off settings including a combined Accurate & Balanced value and Fast (RECGMD_FAST is respected, while RECGMD_BALANCED and RECGMD_ACCURATE are merged to one value)
Supports character sets for the following languages, singly or in combination: English, Brazilian, Danish, Dutch, Finnish, French, German, Italian, Norwegian, Portuguese, Spanish, Swedish.
The MOR module recognizes machine printed text from printed publications, laser or ink-jet printers, and electric typewriters. Output from mechanical typewriters in good condition, and from letter- or near-letter quality (LQ, NLQ) dot-matrix printers is also acceptable.
Supports up to 500 zones on one image.
Supports Omnifont and Draftdot24 filling methods.
The OmniFont
recognition module
- Detects and transmits bold, italic
or underlined text (or any combination)
- Detects and transmits character size
- Classifies font types into three broad categories: serif, sans serif
and monospaced
- Contour analysis-based recognition can be supplemented this with
an innovative form of pattern matching not requiring enormous pre-stored
shape libraries
Provides 3 page-level accuracy and speed trade off settings including Accurate, Balanced and Fast (RECGMD_FAST is respected, while RECGMD_BALANCED and RECGMD_ACCURATE are merged to one value)
Recognizes about 500 characters, including Latin, Greek and Cyrillic alphabets with enough accented letters to recognize the 119 Languages supported by the engine.
There are two ways of modifying incoming images to make them more suitable for this omnifont recognition module:
Standard mode Fax output. (200 x 100 dpi). This switch doubles the pixels in the image’s vertical direction. Faxes sent in Fine Mode (200 x 200 dpi) are preferable. However, if faxes are sent in Fine Mode, then the Standard mode Fax Output should not be used.
Draft 24-pin dot-matrix output. Use the FILL_DRAFTDOT24 filling method to have the character contours smoothed. Again, NLQ or LQ quality output can usually be better recognized without using FILL_DRAFTDOT24.
The Dot Matrix module is designed for ONLY draft-quality 9-pin dot-matrix texts.
For NLQ or LQ texts, the RECOGMODULE_OMNIFONT_PLUS2W, RECOGMODULE_OMNIFONT_PLUS3W, RECOGMODULE_MTEXT_OMNIFONT or RECOGMODULE_MULTI_LINGUAL_OMNIFONT modules are likely to give better results.
If FILL_DRAFTDOT9 filling method is set together with RECOGMODULE_AUTO, RECOGMODULE_MTEXT_OMNIFONT is used, provided that all characters (or languages or filters) validated for the zone are supported by it. If any are not supported, this module is used.
Supports 76 languages, of which 14 have dictionary support: Catalan, Danish, Dutch, English, Finnish, French, German, Greek, Hungarian, Italian, Norwegian, Portuguese, Spanish and Swedish.
Reads multiple languages.
Reads 18 of the 29 punctuation characters. (The Low Double Comma Quotation Mark is missing).
Supports 24 of the 55 miscellaneous characters. (Missing charcters include the Euro Sign, the Small Script F, the Copyright Sign, Registered Trade Mark Sign and the Degree Sign.)
Does not interpret the recognition trade-off setting and cannot be trained.
Used if it is directly specified in a zone structure.
Generates confidence data on recognized characters and can interpret all filter values.
For more information see the LEAD OMR Overview.
This ICR-HNR module can be used for recognition of hand-printed numerals and four additional signs. If further hand-printed characters are to be recognized, the use of the DOC2_RECOGMODULE_RER_PRINTED recognition module is recommended.
This recognition module can recognize the following hand-printed characters:
The digits (0-9)
The Plus Sign (+)
The Minus Sign (–)
The Period or Full-stop (.)
The Comma (,).
The filter DOC2_ZONE_CHAR_FILTER_DIGIT can be used to exclude the last four characters. The filters DOC2_ZONE_CHAR_FILTER_PUNCTUATION and DOC2_ZONE_CHAR_FILTER_MISCELLANEOUS function, other filters have no effect.
The ICR-RER module is a third-party recognition module from reRecognition GmbH, Germany. The engine contains its recognition engine version 4.2f.
This recognition module can be used for recognition of hand-printed alphanumerical characters, i.e. upper and lower case letters, the digits and some others. Although it can be used to read flowing text, its main application area is in form-like situations, where the form designer has great control over the content and maybe length of hand-printed information given in each zone.
The MAT module is designed to read certain groups of fixed-font characters specially designed for OCR or imaging applications, in which no two characters have similar shapes. Each character group has its own filling method. Application areas are in banking, check or waybill handling, product distribution and document validation, where high accuracy can be vital. It also handles some non-fixed print styles.
DOC2_FILL_OCRA
OCR-A. Uppercase English letters (26), digits, some punctuation and 3 special OCR-A symbols:
(OCR Chair)
(OCR Hook)
(OCR OCRFork)
DOC2_FILL_OCRB
OCR-B. Uppercase English letters (26), digits and some punctuation.
DOC2_FILL_MICR
MICR (E-13B). Digits plus some punctuation and 4 special MICR symbols:
(OCR Branch Bank)
(OCR Amount of Check)
(OCR Dash)
(OCR Customer Account
Number)
DOC2_FILL_DOTDIGIT
Ten digits only and the period. Commas are also read, but converted to periods. Though this is in theory a fixed-font, many variants of it are used.
DOC2_FILL_DASHDIGIT
Ten digits only and the period. Commas are also read, but converted to periods. Though this is in theory a fixed-font, many variants of it are used.
The FRX module recognizes machine printed text from printed publications, laser or ink-jet printers, and electric typewriters. Output from mechanical typewriters in good condition, and from letter- or near-letter quality (LQ, NLQ) dot-matrix printers is also acceptable.
Supports Latin, Greek and Cyrillic alphabets with enough accented letters to recognize the 54 languages (Languages and modules).
The PLUS modules recognize machine printed text from printed publications, laser or ink-jet printers and electric typewriters. Output from mechanical typewriters in good condition may also be acceptable.
The PLUS2W and PLUS3W modules use voting technology to provide improved recognition results.
The PLUS2W module combines the results from the MOR and MTX modules.
The PLUS3W module combines the results from the MOR, MTX and FRX modules.
With any of these two voting modules, the accuracy is considerably better, but the recognition may need significantly more time than any single module.
Note: For the Professional engine the image handling algorithms in all modules were changed to deal with practically unlimited image sizes: 32000 pixels in both directions
The following table shows the text recognition module support for each of the 119 languages (General for both Plus and Professional engines):
|
Language |
MOR |
MTX |
FRX |
PLUS2W |
PLUS3W |
DOT |
RER |
|
Afrikaans |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Albanian |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Aymara |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Basque |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Bemba |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Blackfoot |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Brazilian |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Breton |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Bugotu |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Bulgarian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Byelorussian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Catalan |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Chamorro |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Chechen |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Corsican |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Croatian |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Crow |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Czech |
Yes |
Yes |
No |
Yes |
Yes |
No |
Yes |
|
Danish |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Dutch |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
English |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Eskimo (Inuit) |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Esperanto |
Yes |
No |
No |
Yes |
Yes |
No |
No |
|
Estonian |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Faroese |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Fijian |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Finnish |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
French |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Frisian |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Friulian |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Gaelic (Irish) |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Gaelic (Scottish) |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Galician |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Ganda |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
German |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Greek |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
No |
|
Guarani |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Hani |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Hawaiian |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Hungarian |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Icelandic |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Ido |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Indonesian |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Interlingua |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Italian |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Kabardian |
Yes |
No |
No |
Yes |
Yes |
No |
No |
|
Kasub |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Kawa |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Kikuyu |
Yes |
No |
No |
Yes |
Yes |
No |
No |
|
Kongo |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Kpelle |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Kurdish |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Latin |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Latvian |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Lithuanian |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Luba |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Luxembourgian |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Macedonian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Malagasy |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Malay |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Malinke |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Maltese |
Yes |
No |
No |
Yes |
Yes |
No |
No |
|
Maori |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Mayan |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Miao |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Minankabaw |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Mohawk |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Moldavian |
Yes |
No |
No |
Yes |
Yes |
No |
No |
|
Nahuatl |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Norwegian |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Nyanja |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Occidental |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Ojibway |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Papiamento |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Pigin English |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Polish |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Portuguese |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Provençal |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Quechua |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Rhaetic |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Romanian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Romany |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Ruanda |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Rundi |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Russian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Sami |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Sami, Lule |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Sami, Northern |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Sami, Southern |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Samoan |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Sardinian |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Serbian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Serbian, Latinic |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Shona |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Sioux |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Slovak |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Slovenian |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Somali |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Sorbian (Wend) |
Yes |
No |
Yes |
Yes |
Yes |
no |
Yes |
|
Sotho |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Spanish |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Sundanese |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Swahili |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Swazi |
Yes |
No |
No |
Yes |
Yes |
No |
Yes |
|
Swedish |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Tagalog |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Tahitian |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Tinpo |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Tongan |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Tswana (Chuana) |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Tun |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Turkish |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |
|
Ukrainian |
Yes |
No |
Yes |
Yes |
Yes |
No |
No |
|
Visayan |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Welsh |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
Yes |
|
Wolof |
Yes |
No |
No |
Yes |
Yes |
Yes |
Yes |
|
Xhosa |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Zapotec |
Yes |
Yes |
No |
Yes |
Yes |
Yes |
Yes |
|
Zulu |
Yes |
No |
Yes |
Yes |
Yes |
No |
Yes |