Continuing off of my previous blog post about using LEADTOOLS OCR to save screenshots as searchable PDFs, this post demonstrates how to extract the text from those screenshots and store it back into your clipboard as plain text.
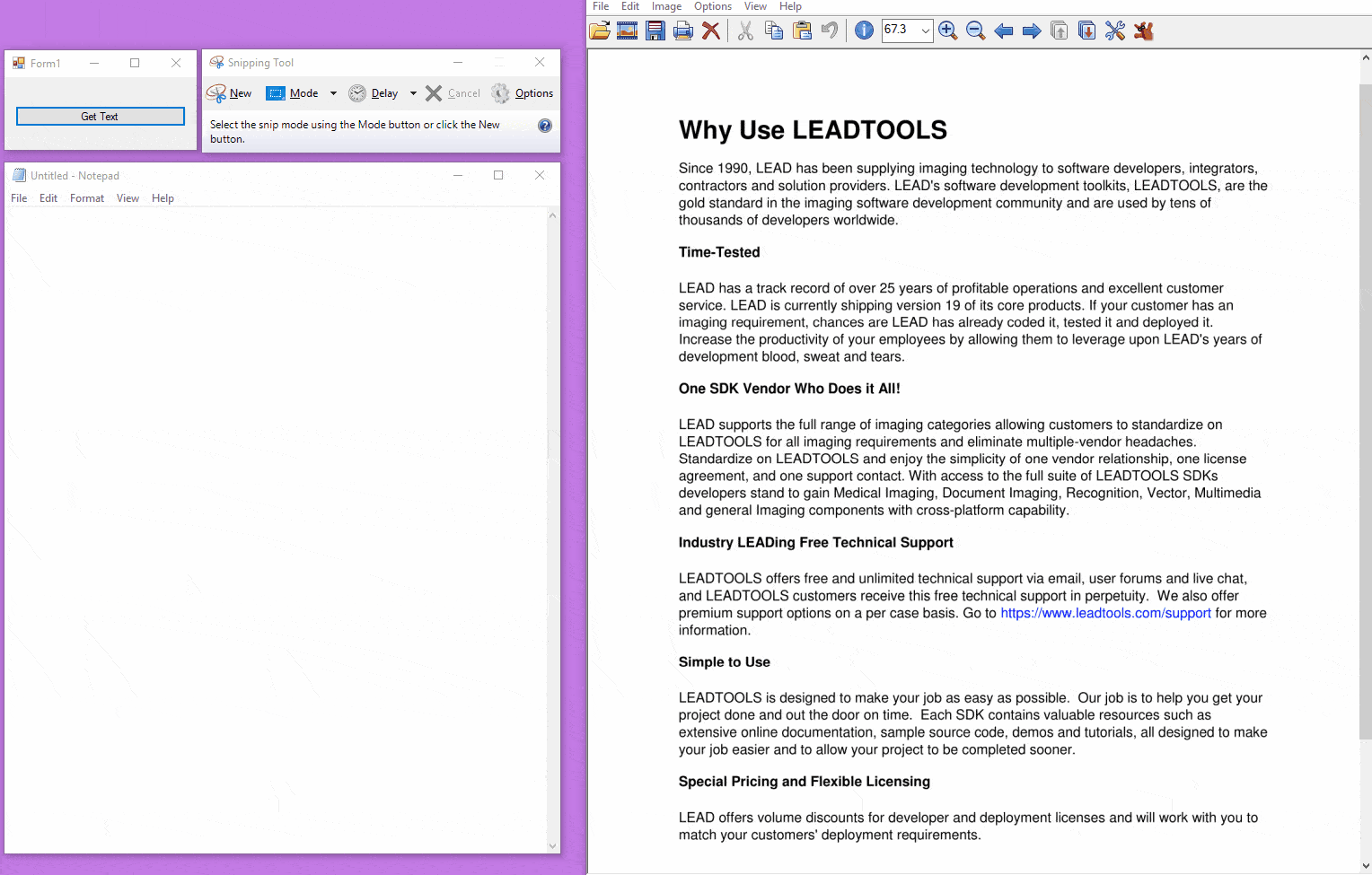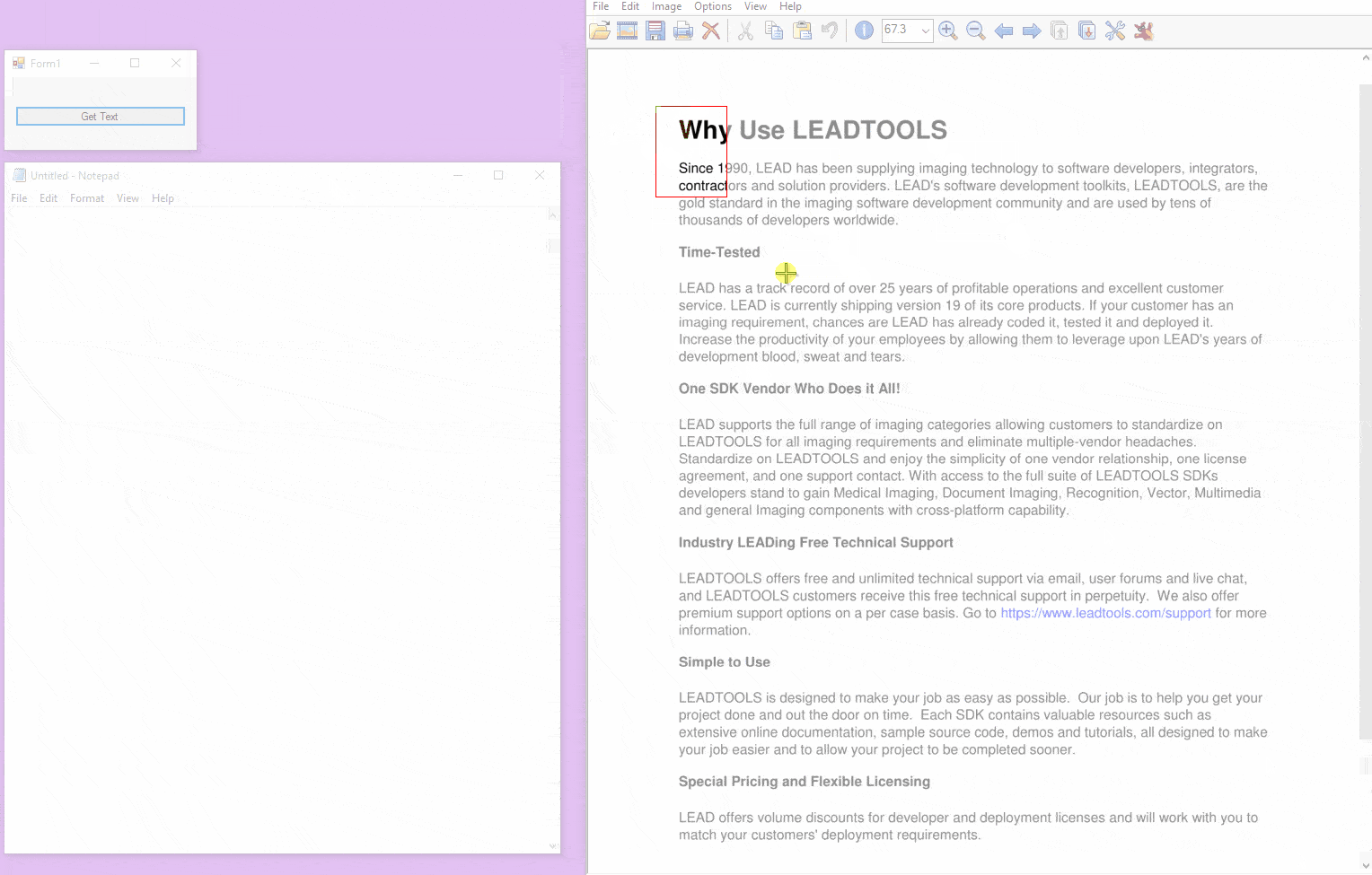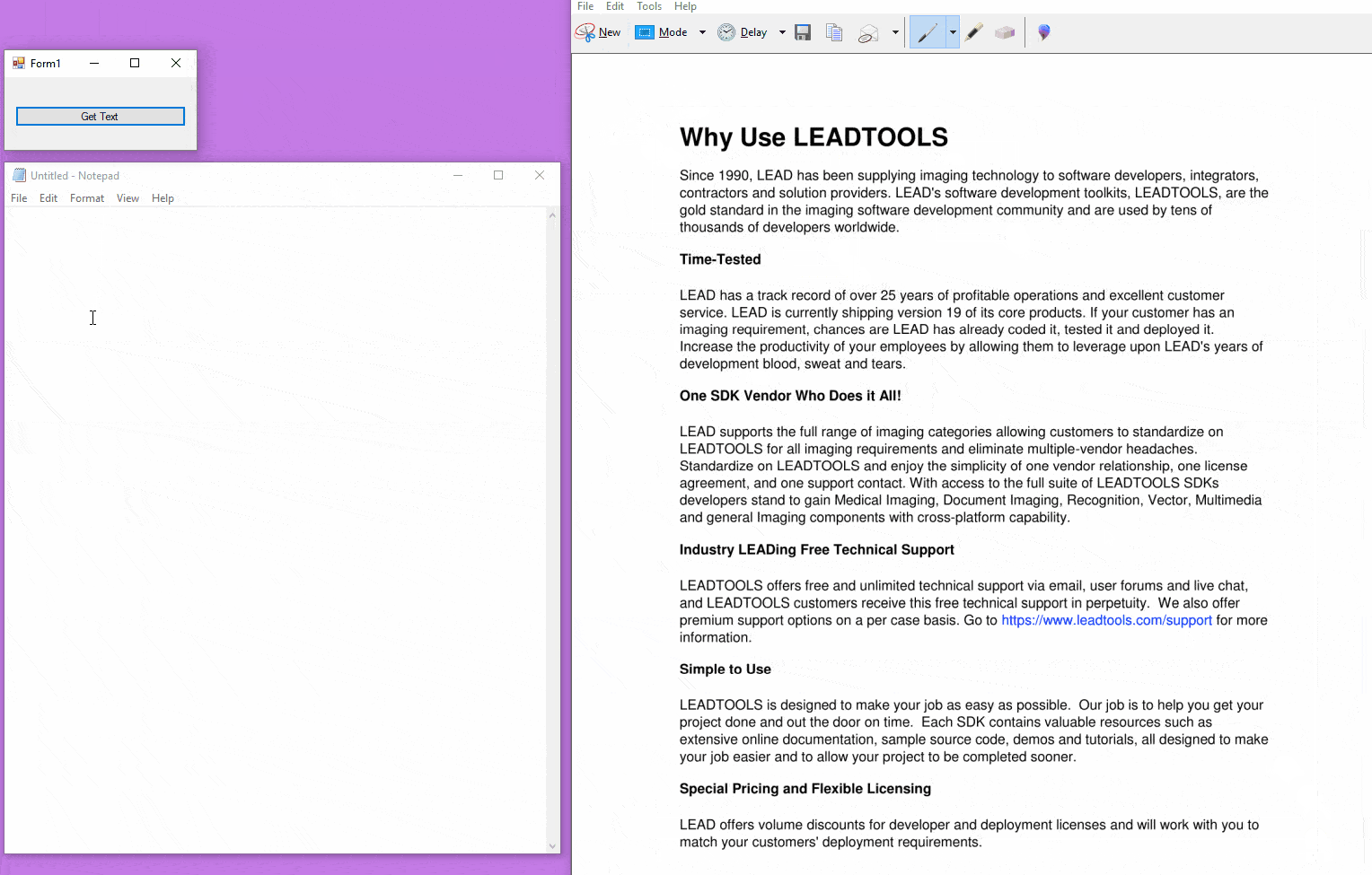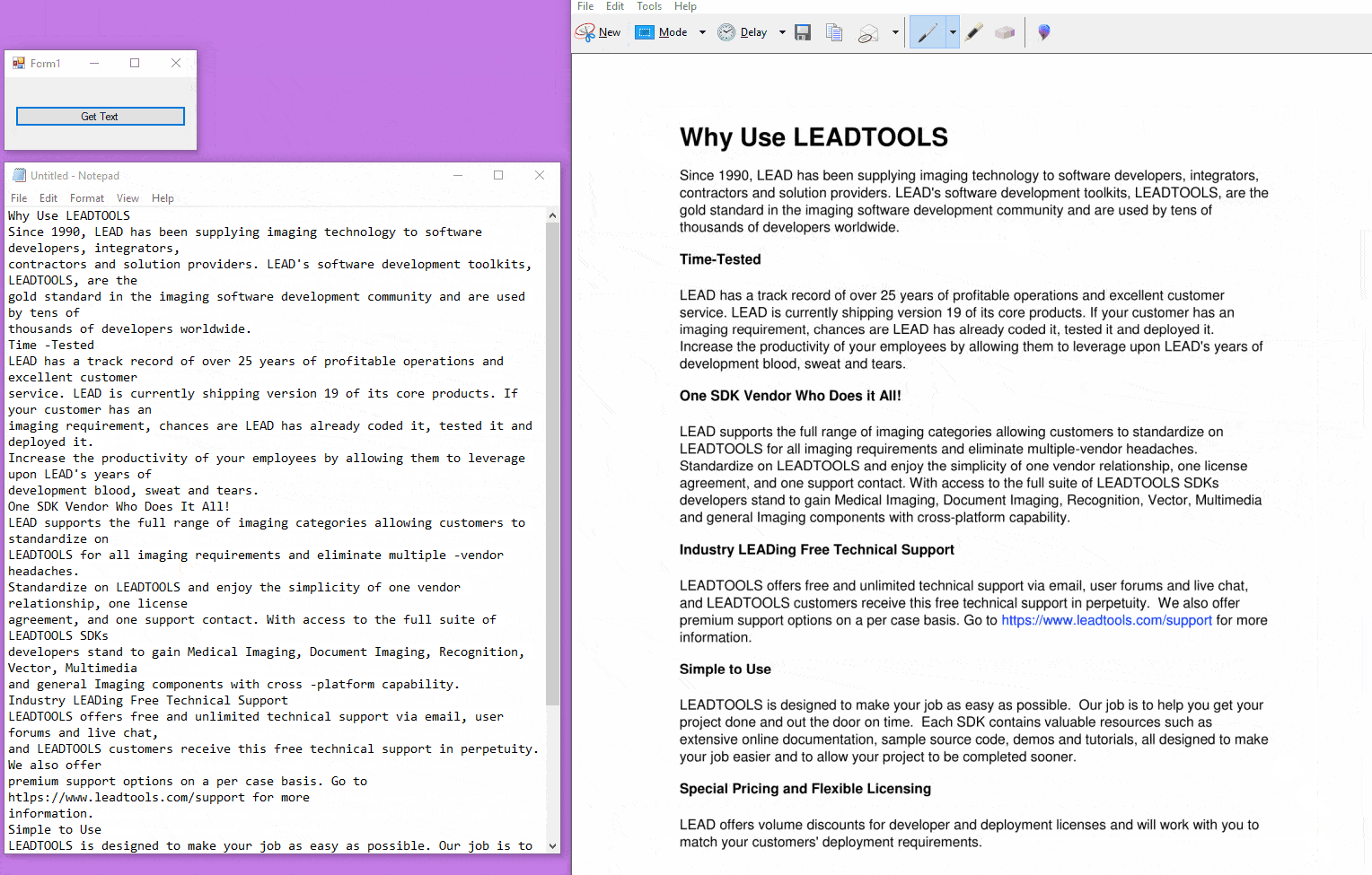
Like I said on the last blog post, developers can get images that have been copied to the clipboard using .NETs Clipboard Class. Instead of saving screenshots as searchable PDFs, this time we'll be using the GetText Method to retrieve text so we can store it back in the clipboard.
The LEADTOOLS GetText Method returns a String containing the recognized characters found or an empty string if zones on the page do not contain recognition data.
Code
string textForClipboard = null;
Image screenshot = GetClipboardImage();
using (RasterImage image = RasterImageConverter.ConvertFromImage(screenshot, ConvertFromImageOptions.None))
{
using (IOcrEngine ocrEngine = OcrEngineManager.CreateEngine(OcrEngineType.LEAD, false))
{
ocrEngine.Startup(null, null, null, null);
// Create an OCR document
using (IOcrDocument ocrDocument = ocrEngine.DocumentManager.CreateDocument())
{
// Add this image to the document
IOcrPage ocrPage = ocrDocument.Pages.AddPage(image, null);
// Auto-recognize the zones in the page
ocrPage.AutoZone(null);
// Recognize it and save it as a TXT file
ocrPage.Recognize(null);
// Get text as string and store it in the clipboard
textForClipboard = ocrPage.GetText(0);
Clipboard.SetText(textForClipboard, TextDataFormat.Text);
}
}
}
public Image GetClipboardImage()
{
Image returnImage = null;
if (Clipboard.ContainsImage())
{
returnImage = Clipboard.GetImage();
}
return returnImage;
}
Need help getting this sample up and going? Contact our support team for free technical support! For pricing or licensing questions, you can contact our sales team ([email protected]) or call us at 704-332-5532.
